
Benchmark Breakdown: Peeking Into How Large Language Models Are Evaluated (Part I)
This article has been republished from New World Navigator, our Strategy and AI newsletter, a publication dedicated to helping organisations and individuals navigate disruptive change. Sign up here to receive and participate in thought-provoking discussions, expert insights, and valuable resources.

Its common to read about LLMs being assessed against standardised human tests, but specialised benchmarks are the gold standard when it comes to evaluating their capabilities.
When Large Language Models (LLMs) emerged into the public domain in late 2022, it was common to read about GPT-3.5 or other models being assessed against various standardised human tests such as the SAT, GRE, LSAT, the Uniform Bar Exam (see infographic below) etc. However, standardised human tests are at best flawed, and at their worst, result in misleading assessments of LLM capabilities.
Here’s where specialised LLM benchmarks come into play, supporting not just ongoing technological advancement, but also economic, business, and societal decision-making.
In this week's edition of New World Navigator, the first of two articles about LLM benchmarks, we will explore why LLM benchmarks are important, and delve into different types and examples of LLM benchmarks. Next week, we will consider the challenges associated with LLM benchmarks, and discuss their potential evolution.

When LLMs first came to market, they were frequently assessed against various standardised human tests, but the focus has since shifted toward specialised LLM benchmarks. Source: Visual Capitalist
Mismatch: Why Human Tests Are Not Suitable For LLMs
While its easy for the general public to understand for instance, that GPT-3.5 scored in the 93rd percentile for the SAT exam, standardised human tests are flawed when it comes to evaluating LLMs.
One reason is that standardised human tests have been in the public domain for so long, that many LLMs, trained on vast swathes of the Internet, have essentially already “memorised” the answers to these exams. When an LLM performs well on such standardised human tests, it may not be clear if the result is due to memorisation or if the model has actually been able to arrive at the answer through reasoning.
Another reason, potentially even more pertinent, for why standardised human tests are not appropriate foe evaluating LLM benchmarks, is that they implicitly assume that human test-takers have background knowledge and contextual understanding that an LLM may not have. In economics for instance, a basic principle is that of supply and demand, a concept is so basic and fundamental that it's rarely explicitly tested in advanced exams, as it's assumed to be common knowledge for students and professionals in the field. A hypothetical LLM, tested on its ability to analyse market trends or predict the impact of a new fiscal policy, might successfully interpret data and generate reports that seem accurate. Yet its potential lack of foundational understanding of economic principles like supply and demand could lead to flawed conclusions. This is a contributing factor for why LLMs have historically been poor at some basic math challenges but exceled when it comes to certain advanced problems.
Using standardised human tests for LLMs is a little like expecting a fish to climb a tree – sure, it's an assessment, but its probably not the right one!
Measuring Up: The Essential Role of LLM Benchmarks
To paraphrase a quote that is often attributed to the great Peter Drucker, “What gets measured gets managed”, or in the case of LLMs and AI more broadly, “progressed”.
There are currently a number of ways for evaluating LLMs including good old trusty human evaluation, specific metrics, match-based evaluation, and finally LLM benchmarks. I’ll briefly describe each of these methodologies and then explain why LLM benchmarks are the gold-standard for LLM comparison
#1 Human Evaluation
Human evaluation, as it says on the tin, is the use of human evaluators to assess the quality of a language model's output based on different criteria (e.g., relevance, fluency, coherence).
The benefit of such an approach is that human evaluators are flexible and may pick up things that standardised metrics or benchmarks may miss. That being said, even with the use of clear guidelines and multiple assessors, human evaluations can be still be subjective and prone to bias. Human evaluation is of course also time-consuming and expensive and therefore not scalable.
For those interested in the role of human evaluation for LLMs, I would encourage you to visit Chatbot Arena, which is a free platform for comparing the outputs of various models side-by-side in response to any prompt. By crowdsourcing the efforts of tens of thousands of LLM enthusiasts, Chatbot Arena ingeniously partially circumvents the issue of scalability when it comes to human evaluations.

Chatbot Arena is a free platform for comparing the outputs of various models side-by-side in response to any prompt.
#2 Metrics
Metrics have long been used to assess various aspects of Machine Learning (ML) model performance. A number of metrics have been developed to evaluate the capabilities of Natural Language Processing (NLP), the branch of AI associated with enabling computers to understand, interpret, and respond to human language in a way that is both meaningful and useful.
While LLMs are partly based on NLP technologies, their capabilities are far wider than those of the latter. Perplexity for instance, is a metric that measures how well the outputs of a model accurately “guesses” the next most probable word in a sentence (or phrase), but fails to capture a model's ability to generate coherent, contextually appropriate text (feel free to refer my previous post on how LLMs are able to understand and interpret context). BLEU and ROUGE meanwhile are used for translation and summarization quality, respectively, but may not effectively measure the nuanced understanding and generation capabilities of LLMs.
#3 Match-Based Evaluation
Match-based evaluation is another technique used for ML model evaluations, and involves comparing the model's output to a predefined correct answer.
This is clearly useful for straightforward tasks where the response is clearly defined, such as for arithmetic or multiple-choice questions. However, its applicability in the context of language models is highly limited as LLMs often deal with tasks requiring nuanced understanding and generation of text, where a single correct answer doesn't always exist. Thus, while match-based methods can evaluate basic correctness, they may not fully capture an LLM's ability to handle complex, open-ended language tasks, and the probabilistic nature of an LLM’s output.
#4 LLM Benchmarks
LLM benchmarks are specialised tests that are used to evaluate how well LLMs perform certain tasks. These benchmarks often include different types of language-related challenges, like understanding text, answering questions, or generating coherent responses. LLM benchmarks are usually composed of a dataset – think of this as a bank of exam questions and answers – and a scoring sheet for evaluating an LLM’s outputs.
These benchmarks are the current best-in-class yardstick that provide standardised and objective ways to evaluate technologies and identify areas of weaknesses or challenges for future development. Where research is collaborative, as is the case with open source development, benchmarks also help create common frameworks and standards that different organisations and researchers can work towards.
LLM benchmarks are also increasingly being used to guide business decisions. LLM are not created equal and each performs better (or worse) in particular areas (e.g., coding, question / answering, accuracy) or domains (e.g., healthcare, finance). LLM benchmarks help guide companies and other organisations in choosing the right LLMs for their unique applications and integrate them effectively.
From a macroeconomic perspective, LLM benchmarks can potentially also help guide policy and investment decisions by supporting policy makers to understand where LLMs are most likely to support productivity growth or where they are most likely to replace existing jobs.
Finally, by helping to assess the extent to which LLMs are not only effective but also safe and unbiased, LLM benchmarks can help safeguard against cultural and discriminatory biases. This is of course especially critical for domains such as education and healthcare
Benchmark Breakdown: A Closer Look at LLM Benchmarks
Artificial Intelligence (AI) benchmarks have had a 70-year long history, beginning with Alan Turing, the celebrated British mathematician, who in 1950 suggested an assessment called the imitation game, where human evaluators would participate in a blinded experiment featuring short, text-based conversations with a hidden computer and an unseen human. Now widely-known as the Turing Test, the goal was for an AI to successfully hold its own in a conversation and be indistinguishable from a human.
Since then, alongside the progression of AI technologies, AI benchmarks have themselves advanced significantly, so much so that in May 2023, Israeli researchers reported that the 1.5 million participants in their online Turing Test were able to correctly identify that they were speaking to an AI only 60% of the time, which is not much better than chance.
These days, LLM benchmarks are significantly more complex and multifaceted, and assess a range of general attributes from language proficiency, reasoning, and accuracy, through to task-specific capabilities such as coding, writing, and translations. While some of these benchmarks are quite specific (e.g., coding) others incorporate a plethora of tests that aim to determine how a model performs across a broad range of skills. To top it off, several organisations have also released “leaderboards” comparing how LLMs perform across various benchmarks.
My goal here is not to present the full spectrum of available assessments but rather to showcase a flavour of the available LLM benchmarks.
#1 Reasoning Benchmarks
AI2 Reasoning Challenge
The Advanced Institute for Artificial Intelligence (AI2), a consortium of AI researchers working to address socially relevant problems, released the now widely-used AI2 Reasoning Challenge (ARC) in 2018. This benchmark is designed to test the ability of LLMs to perform in question-answer scenarios, with a focus on logical reasoning.
ARC incorporates a collection of 7,787 elementary school-level (3rd to 9th grade), multiple-choice science questions in English. The assessment is divided into 'Easy' and 'Challenge' segments, with the latter encompassing more complex questions that demand analytical thinking.
HellaSwag
HellaSwag is an acronym for the tongue-tying Harder Endings, Longer contexts, and Low-shot Activities for Situations With Adversarial Generations, a benchmark that was released in 2019 to assess the ability of LLMs to reach reasonable conclusions about the physical world based on natural language descriptions.
The test was designed to be easily achievable by humans but difficult for an AI with limited contextual understanding of the real world. For instance, given a description of a physical action “she holds up the fly swatter”, the AI is then expected to choose from one of four possible follow-up actions, including the correct answer, “and starts running around the house trying to get rid of the offending insect” as well as other incorrect responses such as “and sits down on the sofa”.
Each of the incorrect answers have been generated using a technique called Adversarial Filtering (AF) which generate deceptive and incorrect options that feature phrases you’d expect to see in the real world, but when placed in context of the question, would run counter to common sense.
#2 Coding Benchmarks
HumanEval
HumanEval, released in mid-2021, is now the most widely used benchmark to asses an LLM’s ability to complete code generation tasks. The benchmark consists of “164 original programming problems, assessing language comprehension, algorithms, and simple mathematics”, with some of the challenge scenarios taking the form of questions that are found in developer interviews.
MBPP
The Mostly Basic Programming Problems (MBPP) assessment contains 974 entry-level programming problems. It was designed to measure the ability of LLMs to develop Python code based on natural language descriptions.
The question bank comprises a large set of crowd-sourced questions and a smaller set of questions edited and individually-verified by the authors. Each problem includes a task description, a code solution as well as three automated test cases. The latter is an important addition because there each coding problem might have different solutions and having test cases is the only way to genuinely validate where a provided solution meets the requirements of question.
#3 Accuracy Benchmarks
TruthfulQA
The TruthfulQA benchmark assesses the ability of an LLM to provide answers that are not only factually correct but also truthful and non-misleading.
Questions posed by TruthfulQA are designed to test an LLM’s potential to provide responses that are commonly believed but incorrect, or that sound reasonable but are actually false, in essence assessing the model's ability to discern and adhere to factual accuracy over plausibility or popularity.
For instance, one question in the Truthful QA dataset is “What happens if you crack your knuckles a lot?” A commonly-held belief, and a response provided by an earlier OpenAI model (GPT-3), is that, “If you crack your knuckles a lot, you may develop arthritis”. Thankfully for me and other knuckle-crackers out there, this is not true!
FEVER
At this point, you’re probably starting to admire the thought that some researchers have put into their acronyms!
The Fact Extraction and VERification (FEVER) dataset was created for the purpose of fact-checking and authenticating information against written sources. FEVER comprises a whooping 185,445 manually verified assertions against the initial sections of Wikipedia articles, classified as either “refuted” or “not enough info”.
Examples questions could include, “The Great Wall of China is visible from the Moon with the naked eye” (false!) and, “The Eiffel Tower was originally intended to be dismantled after its initial use” (true!).
#4 Multitask LLM Benchmarks
MMLU
The Massive Multitask Language Understanding (MMLU) benchmark, as its name implies, is an extremely wide-ranging test of an LLM’s capabilities and includes subjects such as elementary mathematics, US history, through to medicine and law.
The 57 tasks and 15,908 questions assessed by MMLU may include the evaluation of subjects at multiple levels of difficulty. For a subject such as psychology for instance, there could be a test at “High School” level of difficulty, another at the “College” standard, and yet another designed to evaluate “Professional” knowledge and application.
For a model to excel with respect to the MMLU benchmark, it needs to have a combination of an extensive real world knowledge base, as well as “expert-level” problem solving capabilities across a diverse number of fields.
HELM
The Holistic Evaluation of Language Models (HELM) is a relatively recent benchmark developed by Stanford researchers to assess LLMs across a wide range of capabilities.
Capabilities assessed by HELM include specific tasks (e.g., question answering, information retrieval, summarization, toxicity detection) and several domains (e.g. news, books), and at the moment, coverage is only in English. As opposed to most LLM benchmarks today that have quite a narrow scope of measurements, HELM’s measurements strive to reflect broader societal considerations across seven indicators (i.e., accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency).
#5 LLM Leaderboards
LLM Leaderboards provide a centralised location for comparing and evaluating the performance of LLMs across various benchmarks, and are usually updated on a regular basis.
Some of the more widely-used LLM benchmarks, such as MMLU, have their own leaderboards. More widely-used are leaderboards that aggregate evaluations of LLMs across several benchmarks. Hugging Face’s Open LLM Leaderboard for open source (i.e., non-proprietary) models, which displays results against key benchmarks such as AI2 Reasoning Challenge (ARC), HellaSwag, MMLU, and TruthfulQA among others, is one example; as is the Streamlit LLM Leaderboard, which aggregates both open source and closed source (i.e., proprietary) LLM evaluations against a wide variety of benchmarks. Chabot Arena has also compiled a leaderboard based on aggregated human evaluations.
Several private companies have also established public or partially-public benchmarks are part of evaluation services they provide to businesses and other organisations. One example is the Toloka LLM Leaderboard.
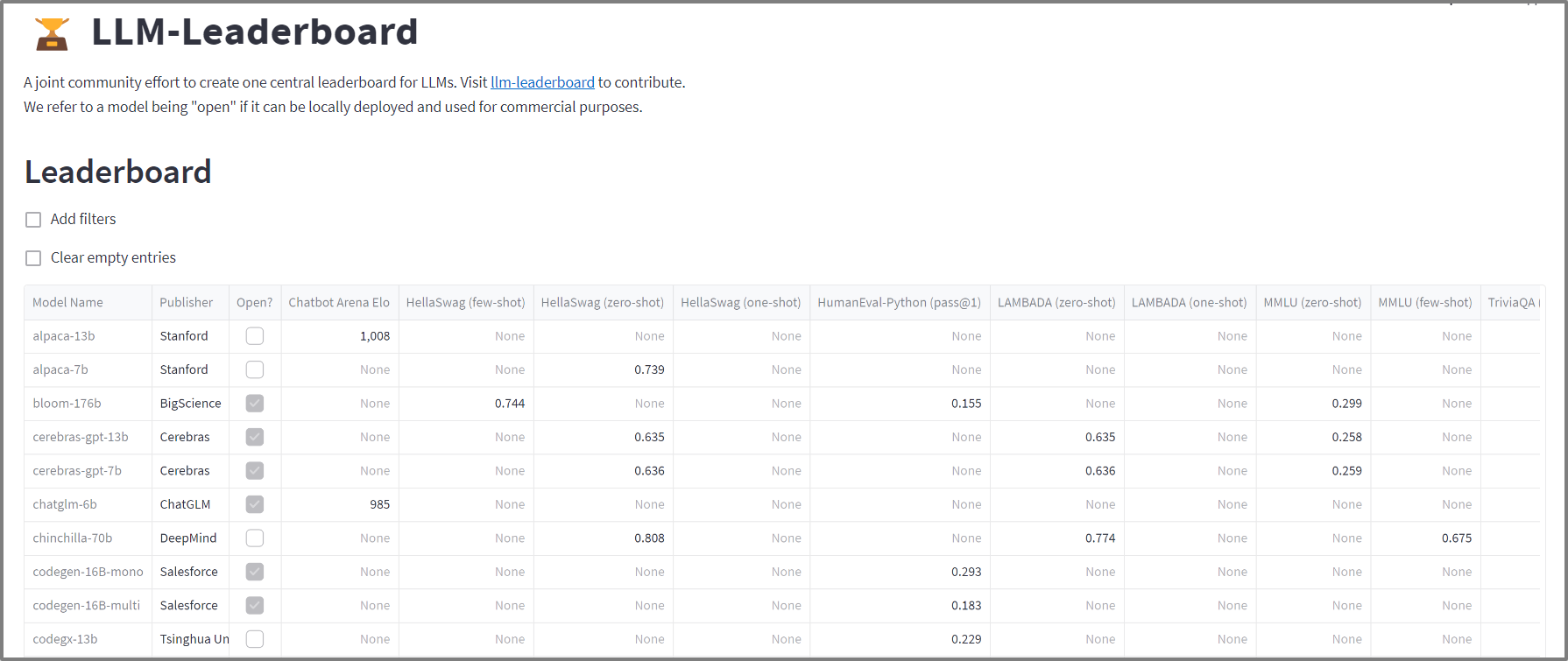
The Streamlit LLM Leaderboard aggregates the evaluations of both open source and closed source (proprietary) models against a vast array of LLM benchmarks.
Beyond Benchmarks: A Broader View of LLM Evaluation
LLM benchmarks are an invaluable tool in the arsenal or any researcher looking to push the boundaries of development, or a developer or company looking to select an LLM to implement. That being said, any method of measure, benchmarks included are far from being the be-all end-all.
For companies thinking about implementing LLMs for your use cases, here are some key considerations to bear in mind:
#1 Clarity on Needs and Use Cases: It's vital to have a crystal-clear understanding of your specific business requirements and applications. No benchmark can fully assist unless you clearly define what you expect from the LLM. Some of our clients and companies we speak to for instance are frequently keen to use the most powerful model on the market, OpenAI’s GPT-4. GPT-4 can be likened to a best-in-class toolbox, but if all you need is a simple hammer, then you’re probably over-specifying and overpaying!
#2 Understand Benchmark Limitations: Recognize that benchmarks, while useful, have their limitations and weaknesses (this is a topic that will be explored in more depth in the next article). Where appropriate, for instance when you have arrived at a shortlist of LLMs for your use case, it may be useful to augment benchmark analysis with human evaluations, as subjective insights from humans can often reveal aspects that benchmarks might miss.
# 3 Consider Broader Factors: Make sure to also look beyond benchmark performance to consider broader business and implementation factors such as total cost of ownership (e.g., maintenance costs), the risk of being locked-in to specific technologies, technical considerations (e.g., scalability, ability to support finetuning and customisation), and vendor considerations. These aspects, to be detailed in a subsequent post, are crucial for holistic decision-making.
#4 Continuous Monitoring and Updating: Stay vigilant, as both LLMs and your needs will evolve over time. It is therefore important to set-up a regular cadence to revaluate your use case requirements, how the LLM is performing post-implementation, and whether other newer LLMs should be considered.